Like many of you reading this article, I have spent an inordinate number of hours watching time whittle away during long-winded estimation sessions in the quest to meticulously break down nebulous requirements into detailed tasks (on very long and very stripy Gantt charts). But worse than the time wasted actually creating these Gantt charts was the significant time spent reworking them on almost a daily basis as the inevitable changes to scope — not to mention adjustments to estimates — flooded in.
It wasn’t long before I realized that the only good to come out of this situation was that we now had some interesting-looking stripy wallpaper to decorate the office with!
And thus began my epic quest to find a more effective approach to help conquer the dark art of estimation. After much searching, I stumbled across what I consider to be the most effective technique for estimating emergent requirements: relative estimation. The elegant simplicity of this new approach finally convinced me that there was in fact some light at the end of the long, dark estimation tunnel.
Estimation Pain
Before jumping into the ins and outs of relative estimation, let’s go right back to basics and consider why estimation is so hard and painful (especially in our software world).
First, we humans are not naturally great estimators. We tend to either be optimists or pessimists and very rarely realists. I don’t even need to back this assertion up with statistics because I am confident that anyone reading this paragraph will agree!
In addition, especially in the world of software, there are numerous unknowns: technology constantly changes and requirements are emergent. There are many moving parts as well as intricate dependencies between tasks (and between people), and that’s not even throwing in external environmental factors!
Why Bother Estimating?
If our estimates carry such a significant chance of being inaccurate, then why bother estimating at all? Well, I believe that even if our estimates aren’t always correct, there are still very important reasons to estimate, and I’m going to talk about two of them.
The first reason is to help us make trade-off decisions. For example, let’s say that I were to ask a couple living in San Francisco whether they would prefer a vacation to Australia or a vacation to Mexico—which one would they choose? Sure, they might have a preference for one or the other, but two other big factors come into play — time and budget. While they might prefer a trip to Australia, let’s say (yes, I’m a little biased), they might not have enough accrued leave (time) to justify the long trip or enough budget (as the Aussie dollar is pretty strong at time of writing!). So how do they calculate whether they can afford to take this particular trip? Well, they simply estimate how long the trip might take and how much the trip might cost. The same principle applies to requirements that make up the wish-lists for our software products.
The second reason is to help set goals. If you’re anything like me, when you set a deadline for yourself, you do everything in your power to make sure you hit it. Sure, there will be times when your estimates are way off—and it shouldn’t necessitate unsustainable heroics—but the act of estimating and setting targets can certainly help you to maintain focus and maximize results.
Now that you’re convinced that estimation is a worthwhile exercise, we can dive right into the details of relative estimation.
Explaining Relative Estimation
Relative estimation is applied at a product backlog level rather than at a sprint backlog level. Sprint backlog items can be estimated in traditional time units (such as hours) primarily because the period of time being estimated for is a single sprint (typically a matter of days rather than months) and the requirements will be defined in enough detail. On the other hand, product backlog items (PBIs) are more loosely defined and may collectively represent many months of work, making time-based estimation very difficult, if not impossible.
Relative estimation applies the principle that comparing is much quicker and more accurate than deconstructing. That is, instead of trying to break down a requirement into constituent tasks (and estimating these tasks), teams compare the relative effort of completing a new requirement to the relative effort of a previously estimated requirement. I’ll use an analogy to demonstrate what I mean.
The Stair Climber
Let’s say we have four buildings. Three of them are modern, while the other is older and somewhat decrepit. They are all different sizes. We are asked to estimate how long it will take us in total to walk to the top floor of all the buildings using the stairs (see Figure 1).

Figure 1 – How do we estimate how long it will take us to walk up all of these buildings using the stairs?
Having never completed an exercise like this, we have some unknowns to consider. For example, we are not sure how physically fit we are or what types of obstacles we might need to negotiate in the stairwells.
So, what do we do? Well, we could take the time to count every floor of every building and then estimate how long it might take us to go up the counted flights of stairs despite not knowing our fitness or the state of the stairwells. This estimate not only will take considerable time but also will be grossly inaccurate if our assumptions are way off the mark.
Let’s explore another option. First, let’s classify the buildings into what we’ll call “effort classes,” with the smallest building considered a 10-point class. The choice of 10 is arbitrary—it could have been 100, 1,000, or any number for that matter (you’ll soon see why it makes no difference). We take a look at building 2, and we think it looks about three times the size of our 10-point building; therefore, we classify it as a 30-point class. Our third building (the older one) is somewhere in the middle, so we would typically call it a 20-pointer, but because of its aging state, there may be more risks and impediments getting up the stairwell, so we take these factors into account and give it a point value of 25. Our final massive building is about twice the size of our second building (the 30-pointer), so it becomes a 60-point class building (see Figure 2).

Figure 2 – We can classify our buildings in relative terms by making some quick comparisons.
Note that these points are simply relative markers to help us compare. The numbers do not relate to a specific unit of size or time—they are just classification markers.
This little exercise allows us to quickly estimate the effort of our four climbs — not in absolute terms but in relative terms. This information forms the first piece of the puzzle. We might now have an idea of the relative effort of climbing one building compared to another, but we still need to work out an estimate for the duration of the overall exercise.
What next? Well, how about we first invest a little time to actually test our fitness and check the state of an indicative stairwell? Let’s time-box this experiment to 10 minutes (our nominated sprint duration) and see how far we manage to get (see Figure 3).

Figure 3 – After 10 minutes of actual stair climbing, we get halfway up the 10-point building.
To the stairwell we go and, after 10 minutes, we find ourselves halfway up build- ing 1 (the 10-point building). With this information, we can work out what our velocity is, or, in other words, the amount of work (in points) that we are able to achieve within our 10-minute sprint. Based on the fact that we climbed halfway up the 10-point building, we can say that our velocity is 5 points per sprint, or more succinctly, 5 points.
“But we need to know how long it will take us to reach the top of all four buildings,” I hear you say? Well, how about some simple extrapolation. Let’s start by totaling the amount of work to do by adding up the relative sizes of the buildings: 10 + 30 + 25 + 60 = 125 points
We then take our velocity (remember, it was 5 points) and, using some simple math, we divide the total 125 points by our 5-point velocity to give us 25 sprints. We know that each sprint is worth 10 minutes, so we have 250 minutes so far. We can then add another 50 minutes (20 percent of our estimated time) for some extra buffer (for catching our breath and for elevator rides back down), and voilá, we can give a rough estimate of 300 minutes, or 6 hours, to complete our exercise!
Software Relative Estimation
Let’s apply this new concept to our software projects. Instead of estimating our stair-climbing prowess, we need to estimate the effort required to complete PBIs.
First, we should determine the effort required to complete a PBI using three factors: complexity, repetition, and risk (see Figure 4).
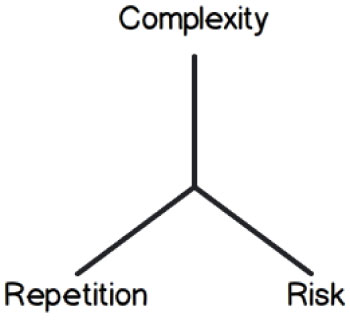
Figure 4 – The three factors that determine how much effort is required to complete a PBI.
Let me explain the difference: we may have a PBI that requires the design of a complex optimization algorithm. It may not require many lines of code but instead a lot of thinking and analysis time.
Next, we may have a PBI that is user-interface focused, requiring significant HTML tweaking across multiple browser types and versions. Although this work is not complex per se, it is very repetitious, requiring a lot of trial and error.
Another PBI might require interfacing with a new third-party product that we haven’t dealt with before. This is a requirement with risk and may require significant time to overcome teething issues.
When sizing up a PBI, it is necessary to take all of these factors into account.
Another point to note is that we don’t require detailed specifications to make effort estimates. If the product owner wants a login screen, we don’t need to know what the exact mechanics, workflow, screen layouts, and so on, are going to be. Those can come later when we actually implement the requirement within a sprint. All we need to know at this early stage is roughly how much effort the login function is going to require relative to, let’s say, a search requirement that we had already estimated. We could say that if the search function was allocated 20 points, then the login function should be allocated 5 points on the assumption that it will require approximately a quarter the effort.
Velocity
We discussed the core purpose of the velocity metric, but there are a few other important factors to be aware of:
- Velocity is calculated by summing up the points of all PBIs completed in a sprint.
- The most common approach for handling partially completed PBIs is to award points only to the sprint in which the PBI actually met its definition of done.
- Although a velocity can certainly be generated with only one sprint, the reality is that it won’t necessarily reflect the longer-term average because velocity tends to fluctuate from sprint to sprint. This fluctuation can happen for a number of reasons, including the impact of partially completed stories, the impact of impediments, and team member availability (or lack thereof), to name just a few. Using an average velocity or rolling average of the last three sprints is a simple option for calculating a more indicative velocity. For an even more comprehensive and accurate calculation of velocity, I recommend you use Mike Cohn’s free velocity range calculator, but note that to use this tool, you need to have data from at least five sprints.
- Velocity is reliant on maintaining the same team makeup and the same sprint length — otherwise, calculating velocity is much harder.
Relative Estimation in Practice
To put relative estimation into practice, many teams play a nifty game called Planning Poker. My article “Planning Poker at Pace” explains the mechanics of this effective technique and offers a selection of tips and tricks to make it as effective and efficient as possible.
Speaking of practice, it is important to understand and accept that estimation is hard. Very hard. Software development is burdened with high levels of complexity (and many unknowns), yet it requires perfection for the software to compile and work. Because of these factors, no estimation approach is going to be foolproof. However, I truly believe that relative story point estimation is, at the very least, just as accurate as any alternative while offering the advantage of being far more simple and elegant in comparison.
If you liked this article, you can:
Subscribe to this RSS feed!
Find out more about relative estimation by taking one of our CSM training courses.





















")















































































Hi Ilan,
Great article, In the past I’ve often had senior stake holders trying to relate a time or dollar figure to story points to get their head around the idea, and even then they would struggle. I think the buildings analogy is a perfect way to explain the concept to them, cheers!
Richard
Hi Richard – thanks and glad you found the article helpful. I really try to avoid pinning an exact time/$ to a story point value as it is not supposed to have a direct mapping. Using ranges is much safer and realistic.
> So how have you handled the explanation of relative estimation to your stakeholders?
I don’t, because I don’t usually want to bog them down with that detail. In find that most stakeholders don’t want to care about points, they care about things they understand — days, dollars and months. I usually know the rough average velocity of the team and just relate it to what translates into a range of days. If they want to know when a set of features will be complete, assuming the team has estimated already in points, I translate into a range of days, and give the “this is about how fast it will get done with the current team” or “this is about how much effort will be involved at the rate we’re moving now”.
I just don’t think stakeholders should have to care about story points.
Hi Charles – this is good advice. Emphasis on your point about translating to a ‘range’ rather than specifics.
I liked the buildings example
Initial estimation is indeed a problem. Not because of relative estimations, but in general. How do you know how fast you can cut pineapples if you never did. That’s hard in story points as well as ideal days.
I was recently training for a marathon, but I had a bonk, no energy, in the middle. Far from home, far from the next village. I decided to stop the training and take the bus home. Seeking half in delirium for the next bus stop I asked a farmer how long it would take me to the next bus stop. He replied that he has no idea. So I walked off in a direction. Suddenly he shouted: “20 Minutes”. I replied that he could have told me that earlier, but he replied that he did not know my velocity.
Initial estimation is hard. I think even it is impossible. You have to setup a team doing some work and only then they can estimate basing on their experience.
Hi Daniel – thanks for sharing your marathon story – well done for giving it a go! Indeed you are correct – velocity is key to estimation and the more sprints that have been run to obtain an indicative velocity the better.
I like the idea of story points as unitless placeholders that don’t really describe time until you are a few sprints in. In reality, your understanding of how long things will take doesn’t get even decent until halfway though the project. By that point, you’ll have enough data from previous sprints to assign reasonable times to your remaining stories.
Hi Dave – yep agree that estimation becomes much more meaningful as your sprints progress but at the end of the day you have to start somewhere…
[…] an excellent article expounding the benefits of relative planning at Scrum Shortcuts: Unlike traditional estimation units such as ‘ideal days’, the measurement unit utilized during […]
Hats off to you IIan, I was looking for some verbiage to help my team tomorrow really grasps the whole Story Pointing concept. Makes perfect sense to me so they should just get it, right?
Okay so seriously it’s important to convey this almost like a Teacher to see your students really get it, the lights come on. I’ve read quite a bit of materials over time though this article really helps with those newbies to Scrum and especially the more skeptical Management type.
Thanks so much, Melissa
It is very clear and easy to understand explaination. Thanks for your post.
~Cheers
Hi Ilan,
Thank you for writing this great article and more importantly, for sharing the example of climbing buildings to explain the concept of relative sizing (estimation). I found it very effective. I am co-teaching a CSM class next week, and plan to use it during the class to explain the concept of relative estimation. Great job!
Cheers!
Excellent! I understood relative estimation and velocity so well… Thanks for this…
good examples!
[…] compare between options. Humans are bad at estimating in absolute units. We are much better at relative estimation and […]
Hi Ilan,
Thanks for explaining it in so simple way.
Regards
Rohit
One of the best articles I’ve read about Relative estimation. Thanks a ton Ilan!